Notionの画像(S3)をCloudflare R2に格納する
Notionで作成されたマークダウンコンテンツには、Amazon S3に保存された画像へのリンクが含まれています。ブログ記事として公開する際に、これらの画像をCloudflare R2ストレージなどの外部ストレージに移行することで非公開ページの画像も表示することができます。この記事ではNotionのページに添付されている画像をCloudflare R2に格納する処理について解説します。
目次
画像移行処理の概要
Notion からエクスポートされたマークダウンにおいて S3 の画像を R2 に移行する処理は、以下の 4 つのステップで行われます。
- マークダウンから画像記法と URL を抽出する
- 各画像を S3 からダウンロードする
- ダウンロードした画像を R2 にアップロードする
- マークダウン内の画像リンクを新しい R2 の URL に置換する
これらを効率的に実行するために、Cloudflare Workers の制約(実行時間、メモリ、CPU 使用量)を考慮することが重要です。
多数の画像を含む Markdown でもスムーズに動作するように、並列処理の仕組みを導入しています。
実装したソースコード
R2 への画像移行処理を実装するにあたり、「シンプルさ」と「効率性」のバランスを重視しました。実装したソースコードを見ていきましょう。
/**
* マークダウン内の画像URLをCloudflare R2に保存し、R2のURLに置き換える
* シンプル化バージョン - Notionの画像記法に特化
*/
type ProcessImagesParams = {
markdown: string;
r2PublicUrl: string;
r2Bucket: R2Bucket;
};
export async function processAndUploadImages({
markdown,
r2PublicUrl,
r2Bucket,
}: ProcessImagesParams): Promise<string> {
// 全ての画像記法をキャプチャ (Notionでは  の形式)
const imagePattern = /!\[(.*?)]\((.*?)\)/g;
const processedUrls = new Map<string, string>();
const uploadPromises: Promise<void>[] = [];
// 全てのマッチを検出
const matches = [...markdown.matchAll(imagePattern)];
if (matches.length === 0) return markdown;
// 処理対象のURLを収集(altテキストがURLの場合のみ処理)
const urlsToProcess = matches
.filter((match) => match[1].startsWith('https://')) // altテキストがURLのもののみ
.map((match) => match[1]); // 画像URL部分を抽出
// 重複を除外
const uniqueUrls = [...new Set(urlsToProcess)];
if (uniqueUrls.length === 0) return markdown;
// 各URLに対して並列処理を準備
for (const imageUrl of uniqueUrls) {
uploadPromises.push(
processImage(imageUrl, r2Bucket, r2PublicUrl, processedUrls)
);
}
// 全ての画像処理を並列実行
await Promise.allSettled(uploadPromises);
// 処理済みURLがなければ元のマークダウンを返す
if (processedUrls.size === 0) return markdown;
// URLの置換処理(一度の処理で全ての置換を行う)
return replaceMarkdownUrls(markdown, processedUrls);
}
/**
* 1つの画像を処理する関数
*/
async function processImage(
imageUrl: string,
r2Bucket: R2Bucket,
r2PublicUrl: string,
processedUrls: Map<string, string>
): Promise<void> {
try {
// 画像ファイル名の生成 (ユニーク性を確保)
const fileName = extractFileName(imageUrl);
const safeFileName = `images/${fileName}-${Date.now()}.png`;
// 画像をダウンロード
const response = await fetch(imageUrl);
if (!response.ok) {
console.error(
`画像のダウンロードに失敗: ${imageUrl}, ステータス: ${response.status}`
);
return;
}
// 画像データを取得してアップロード
const imageData = await response.arrayBuffer();
await r2Bucket.put(safeFileName, imageData, {
httpMetadata: {
contentType: response.headers.get('content-type') || 'image/png',
},
});
// マッピング情報を保存
const publicUrl = `${r2PublicUrl}/${safeFileName}`;
processedUrls.set(imageUrl, publicUrl);
console.log(`画像アップロード成功: ${publicUrl}`);
} catch (error) {
console.error(
`画像処理エラー (${imageUrl}): ${error instanceof Error ? error.message : error}`
);
}
}
/**
* URLからファイル名を抽出する関数
*/
function extractFileName(url: string): string {
const defaultName = `image-${Date.now()}`;
try {
const urlPath = new URL(url).pathname;
const fileName = urlPath.split('/').pop() || defaultName;
// クエリパラメータを除去
return fileName.split('?')[0];
} catch {
return defaultName;
}
}
/**
* マークダウン内のURL参照を置き換える関数
*/
function replaceMarkdownUrls(
markdown: string,
urlMap: Map<string, string>
): string {
let result = markdown;
for (const [s3Url, r2Url] of urlMap.entries()) {
// 正規表現をシンプルにし、エスケープを適切に行う
const escapedUrl = s3Url.replace(/[.*+?^${}()|[\]\\]/g, '\\$&');
const pattern = new RegExp(`!\\[${escapedUrl}\\]\\(.*?\\)`, 'g');
// 新しい形式に置き換え
result = result.replace(pattern, ``);
}
return result;
}このコードは、マークダウン内の S3 画像 URL を検出し、Cloudflare R2 へ登録を行います。
次のセクションで各関数の詳細を説明します。
主要関数の詳細解説
processAndUploadImages関数
メインの処理を担当する関数です。次のような流れで画像の移行を行います。
export async function processAndUploadImages({
markdown,
r2PublicUrl,
r2Bucket,
}: ProcessImagesParams): Promise<string> {
// 全ての画像記法をキャプチャ (Notionでは  の形式)
const imagePattern = /!\[(.*?)]\((.*?)\)/g;
// ...
}この関数の特徴は以下の通りです。
- シンプルな正規表現で画像記法を検出
- Notion の特殊な記法(alt テキストが URL になっている)に対応
- 重複 URL の処理を省くための最適化
- 並列処理による高速化
processImage関数
個々の画像のダウンロードとアップロードを担当します。
この処理は並列処理の最中で呼び出されます。各画像の処理は独立しているため、別々の Promise として可能です。
エラーが発生しても他の画像処理には影響しないという利点もあります。
async function processImage(
imageUrl: string,
r2Bucket: R2Bucket,
r2PublicUrl: string,
processedUrls: Map<string, string>
): Promise<void> {
// ...
}この関数では次の処理を行います。
- 画像のファイル名を抽出して一意のファイル名を生成
- S3 から画像をダウンロード
- R2 に画像をアップロード
- 処理結果をマッピング情報として保存
格納した画像はこのような形式になっています。
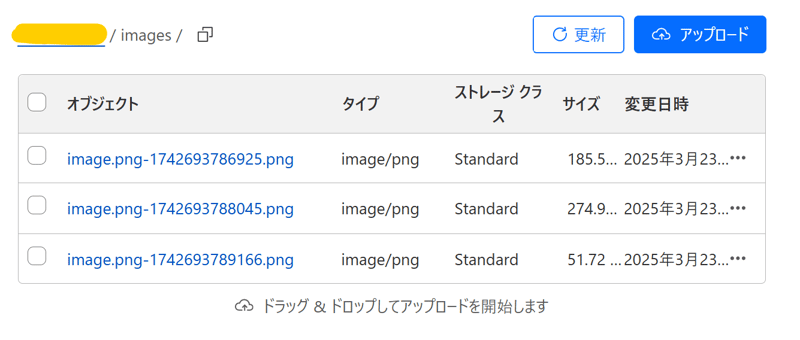
extractFileName関数
URL から安全にファイル名を抽出する関数です。
function extractFileName(url: string): string {
// ...
}この関数の特徴は以下の通りです。
- URL オブジェクトを使用した安全な URL 解析
- クエリパラメータを除去したファイル名の取得
- エラー時のフォールバック処理
replaceMarkdownUrls関数
マークダウン内の URL 参照を新しい R2 の URL に置き換える関数です。
function replaceMarkdownUrls(
markdown: string,
urlMap: Map<string, string>
): string {
// ...
}この関数では次の処理を行います。
- URL の特殊文字を正規表現でエスケープ
- マークダウン内の画像記法を検索
- 新しい R2 の URL に置き換え
実装時の注意点
並列処理による効率化
このコードでは、Promise.allSettled() を使用して複数の画像を並列処理しています。
画像のダウンロードはネットワーク待ちが発生するため、直列処理だと時間がかかりすぎます。
並列処理にすることで、10 枚の画像があっても基本的には 1 枚分の処理時間で済みます。
// 全ての画像処理を並列実行
await Promise.allSettled(uploadPromises);Promise.all() ではなく Promise.allSettled() を選んだのは、一部の画像処理に失敗があっても他の処理を続行させるためです。
ブログ記事の場合、一枚の画像が表示できなくても記事全体を表示できないよりはマシです。
Promise.all() - JavaScript | MDN
Promise.all() は静的メソッドで、入力としてプロミスの集合の反復可能オブジェクトを取り、単一の Promise を返します。この返却されたプロミスは、入力されたプロミスがすべて履行されたとき(空のイテレーターが渡されたときを含む)、その履行された値の配列で、履行されます。入力されたプロミスのいずれかが拒否されると、その最初の拒否理由とともに拒否されます。

Promise.allSettled() - JavaScript | MDN
Promise.allSettled() は静的メソッドで、入力としてプロミスの反復可能オブジェクトを受け取り、単一の Promise を返します。この返されたプロミスは、入力のすべてのプロミスが決定したとき(空の反復可能オブジェクトが渡された場合を含む)に履行され、各プロミスの結果を記述するオブジェクトの配列が返されます。
最適な正規表現の活用
Notion からエクスポートされたマークダウンを処理するにあたり、できるだけシンプルな正規表現を選びました。
const imagePattern = /!\[(.*?)]\((.*?)\)/g;複雑な正規表現は保守性が低下するため、基本的なマークダウン記法にマッチするシンプルなパターンを採用しています。
以前の実装では prod-files-secure.s3 などの特定のドメインを検索していましたが、将来的な URL の変更に対応できるよう汎用的な形にしました。
Notion の特殊な記法(alt テキストが URL になっている)は正規表現では捉えず、フィルタリングで対応しています。
.filter(match => match[1].startsWith('https://')) // altテキストがURLのもののみこの方法だと、将来的に Notion の出力形式が変わっても、フィルタ条件だけを変更すれば対応できます。
重複URLの最適化
同じ画像が記事内で複数回使用されている場合、同じ画像を何度もダウンロード・アップロードするのは非効率です。そこで Set を使って重複排除しています。
const uniqueUrls = [...new Set(urlsToProcess)];例えば同じ画像が 10 回使われていても、ネットワーク転送は 1 回で済みます。
特に Cloudflare の Worker 環境では、CPU リソースよりもネットワークリクエストの方がコストが高いため、この最適化は重要です。
Limits
Cloudflare Workers plan and platform limits.
ファイル名の生成
R2 にアップロードする際のファイル名には、オリジナルのファイル名を可能な限り保持しつつ、一意性を確保するためにタイムスタンプを付与しています。
const fileName = extractFileName(imageUrl);
const safeFileName = `images/${fileName}-${Date.now()}.png`;この命名規則には以下のメリットがあります。
- 元のファイル名を維持することで、コンテンツの追跡が容易
- タイムスタンプにより名前の衝突を回避
images/フォルダに分類することで、R2 内での管理が容易
まとめ
今回の実装は、特に Cloudflare Workers の制約を考慮した設計になっています。Cloudflare Workers は実行時間やメモリに制限があるため、最適化されたコードが求められます。
将来的には WebP 形式への変換は画像の縮小、キャッシュ戦略を駆使して配信速度を向上させていきたいですね。